Gebruik routinematig verzamelde zorgdata als onderzoeksbron
Plaats een reactie
Onderzoek doen op basis van routinematig verzamelde zorggegevens biedt grote kansen. Maar met die kansen wordt nog veel te weinig gedaan, vinden vier deskundigen. Ze tonen de vele mogelijkheden.
Routinematig verzamelde zorgdata – vastgelegd ten behoeve van het zorgproces – bevatten informatie over zorggebruik, zorgbehoefte en soms over uitkomsten of kwaliteit van zorg. Op basis hiervan kunnen vele inzichten ontstaan die te gebruiken zijn voor kwaliteitsverbetering van de zorg. Wat het kost aan geld, tijd en moeite om data te verzamelen voor onderzoek, kun je besparen door routinematig verzamelde zorggegevens te gebruiken.
Het Nederlandse datalandschap is echter versnipperd en het is voor onderzoekers vaak ingewikkeld deze data te verkrijgen. Onlangs werd in dit blad geschreven over één loket voor alle medische data, waar stichting Health-RI zich de komende jaren voor zal inzetten (MC 16/2021:18). Dat geeft een mooi toekomstperspectief, maar de onderzoeker die morgen al aan de slag wil loopt nog tegen allerlei problemen aan. In dit artikel beschrijven wij, in vier stappen, onze eigen ervaringen met onderzoek op basis van routinematig verzamelde gegevens en bieden we onderzoekers praktische handvatten om deze waardevolle data ook nu al makkelijker en sneller te kunnen bemachtigen. We gebruiken twee casussen ter illustratie om onze ervaringen te delen en beschrijven mogelijkheden, knelpunten en oplossingen.
Stap 1: Benodigde data in kaart brengen
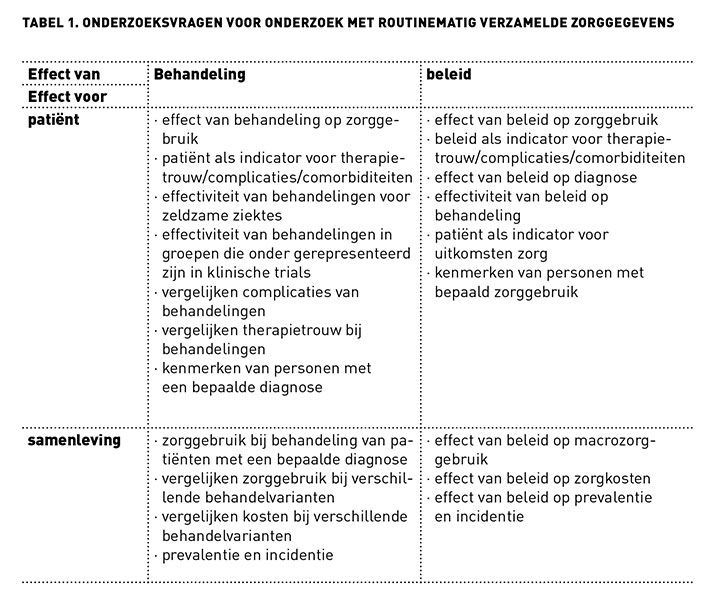
Routinematig verzamelde zorggegevens hebben voor- en nadelen voor het doen van onderzoek. Ze zijn vooral voor bepaalde onderzoeksvragen geschikt (zie tabel 1).
We nemen als voorbeelden het doen van onderzoek naar praktijkvariatie in de chirurgische behandeling van een lagerughernia en het onderzoek naar praktijkvariatie bij recidiverende keelonstekingen bij kinderen. Het had een aantal voordelen om hier routinematig verzamelde zorggegevens voor te gebruiken. Ten eerste kostte het minder tijd, geld en moeite, omdat deze data voor onderzoek niet apart verzameld hoefden te worden. Ten tweede bevatten de data informatie over de algemene populatie, de dagelijkse praktijk, waardoor ze zeer representatief waren. Data van patiënten die bij klinische studies geëxcludeerd worden, bijvoorbeeld doordat zij ernstige comorbiditeiten hebben, zijn beschikbaar. De externa validiteit van dit onderzoek is daardoor hoog. Ten derde was het mogelijk om analyses te maken van grote groepen patiënten met een lange follow-up en weinig uitval. Zo konden we zoveel mogelijk ziekenhuizen includeren. Zelf data verzamelen over meerdere jaren in meerdere ziekenhuizen, zou ontzettend veel tijd hebben gekost.
Het is echter noodzakelijk om je als onderzoeker bewust te zijn van de belangrijkste inhoudelijke beperkingen van routinematig verzamelde data. Allereerst hebben ze een beperkt detailniveau, omdat ze primair voor andere doeleinden worden verzameld dan voor onderzoek. Met name is er een beperkt detailniveau in diagnoses. Hierdoor kon in de genoemde casus over recidiverende keelontstekingen bijvoorbeeld geen onderscheid worden gemaakt tussen de diagnose ‘tonsillitis’ of ‘peritonsillair abces’. Verder kan informatie over de gezondheidstoestand en ernst van de ziekte onbreken. Dit leverde problemen op bij de casus over de rughernia. Zo kon alleen in kaart gebracht worden of patiënten een rughernia hadden, maar niet hoeveel en hoe lang zij hier last van hadden. Doordat de ziekte-ernst niet bekend was, kon geen eenduidige uitspraak worden gedaan over de mate van overbehandeling of onderbehandeling. Ook belangrijke uitkomsten zijn niet altijd geregistreerd.
Ten tweede zijn patiënten in databases vanzelfsprekend niet gerandomiseerd, waardoor bias kan optreden in onderzoeksresultaten. Er zijn statistische methodes bekend om de baseline karakteristieken van groepen te matchen. Hiervoor is het echter wel van belang dat belangrijke variabelen bekend zijn en dat is, mede door het lage detailniveau van de data, niet altijd het geval. Verder kunnen regionale verschillen een relatie hebben met zowel de patiëntkarakteristieken als de uitkomsten van een behandeling. Dit compliceert bijvoorbeeld het uitvoeren van effectiviteitsonderzoek met deze data.
Tot slot kunnen codes veranderen in de loop der tijd, waardoor data over de jaren heen niet altijd volledig vergelijkbaar zijn.
Stap 2: Keuze voor een database
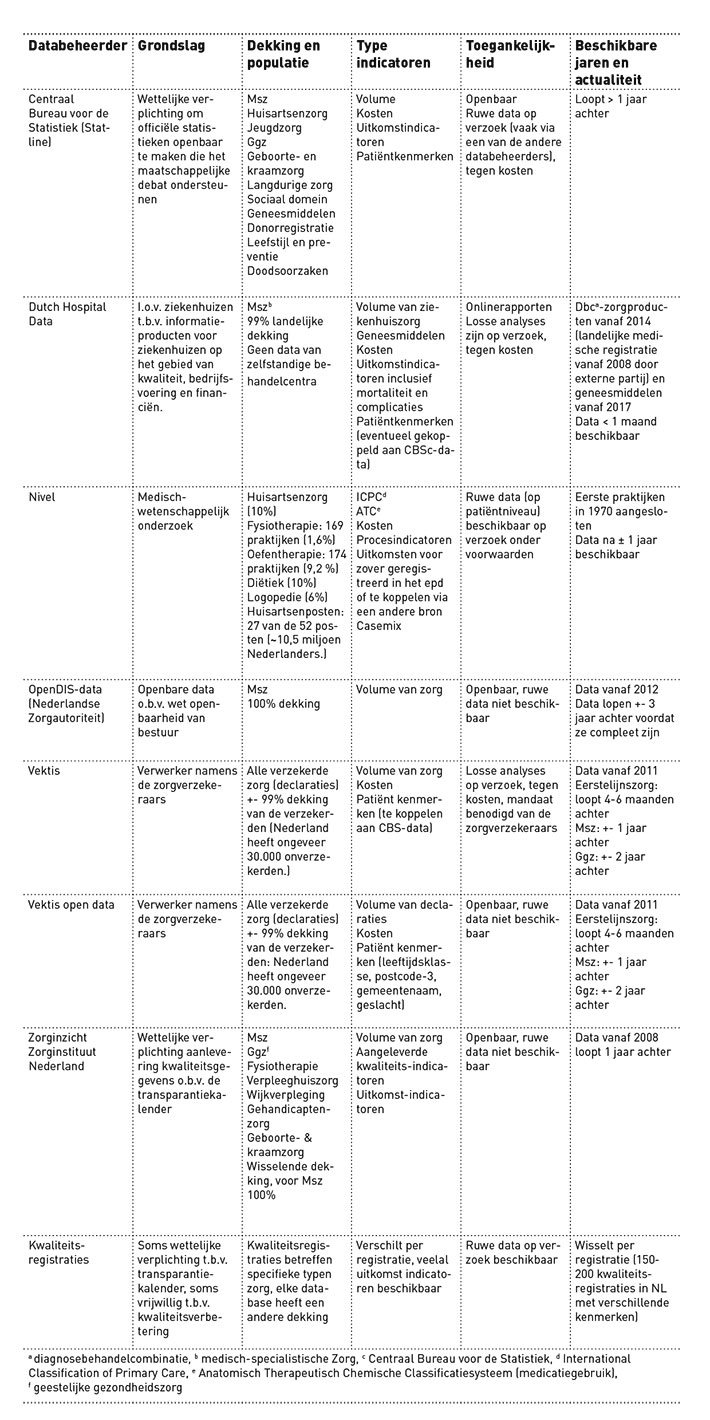
Routinematig verzamelde zorggegevens worden door verschillende databeheerders verzameld en opgeslagen. Dit geeft een grote verscheidenheid in beschikbare indicatoren en in dekking en actualiteit van de data. Deze kenmerken zijn van belang voor het kiezen van een databeheerder. Om deze keuze te vergemakkelijken, geven wij in tabel 2 een overzicht van de kenmerken van de grootste Nederlandse databeheerders.
De grootste bron van routinematig verzamelde gegevens zijn de declaratiedata. Deze worden verzameld door Vektis (Zorgverzekeraars Nederland), DHD (Dutch Hospital Data, beroepsvereniging van NVZ & NFU), de open DIS-data (NZA) en het CBS. DHD verzamelt naast de declaratiedata de Landelijke Basisregistratie Zorg, waarin ICD-data en aanvullende zorgactiviteiten worden geregistreerd. De CBS database bevat ook data over sociaal-economische kenmerken. Het Nivel verzamelt data over eerstelijnszorg. Daarnaast zijn er meer dan honderd kwaliteitsregistraties in Nederland over uiteenlopende klinische onderwerpen zoals perinatale zorg, cardiologische zorg en oncologische zorg. In het kader van de transparantiekalender worden allerlei volume-, proces- en structuurindicatoren verzameld in de zorginzichtdatabase.
Voor het onderzoek naar praktijkvariatie in de behandeling van een lagerughernia was het de onderzoekers pas laat in het aanvraagtraject duidelijk dat DHD geen data heeft van zelfstandige behandelcentra (zbc’s). Heel relevant, aangezien een gedeelte van de chirurgische zorg voor een lagerughernia in zbc’s uitgevoerd wordt. De Vektis-data zijn hiervoor meer geschikt, omdat deze wel data over zbc’s bevat.
Verder liepen we er in deze casussen tegenaan dat het datalandschap in Nederland versnipperd is. Hierdoor kunnen databronnen niet altijd gekoppeld worden én moeten onderzoekers bij verschillende dataleveranciers data aanvragen. Voor het praktijkvariatieonderzoek naar de tonsillectomie betekende dit dat er wel toegang was tot een database met gegevens over huisartsenzorg in een bepaalde regio, maar dat deze niet gekoppeld kon worden aan de database waarmee praktijkvariatieonderzoek gedaan was op ziekenhuisniveau. Er is momenteel onduidelijkheid over wettelijke mogelijkheden om databases te koppelen. De sites van DHD en Vektis vermelden dat het maken van koppelingen tussen databases problematisch is in verband met wet- en regelgeving rondom privacy, terwijl de wet- en regelgeving wel de ruimte biedt om deze data te hergebruiken voor onderzoeksdoeleinden. Het is natuurlijk terecht dat data-aanvragen juridisch correct moeten zijn, maar wat correct precies inhoudt wordt verschillend geïnterpreteerd. Eén loket voor alle medische onderzoeksdata zou een goede oplossing kunnen zijn om de aanvraag voor datakoppelingen te vereenvoudigen. Daarnaast kan juridische ondersteuning de onderzoeker helpen bij het onderbouwen van de data-aanvraag.
Stap 3: Aanvragen van de data
Sommige databases, zoals openDIS en de Zorginstituut Nederland (ZiNL)-transparantiekalender zijn vrij toegankelijk, maar voor de meeste databases moeten onderzoekers toestemming verkrijgen om de data te gebruiken. Toestemmingsprocedures voor dataverzoeken duren soms maandenlang, terwijl niet duidelijk is waardoor dat komt. Voordat onderzoekers een data-aanvraag doen, moeten zij zich informeren over de geldende voorwaarden. Zo stelt het Nivel bijvoorbeeld verplicht dat onderzoeksuitkomsten openbaar gepubliceerd worden en er ten minste één onderzoeker van Nivel meeschrijft. Een ander voorbeeld is dat Vektis-data alleen gebruikt mogen worden als een project maatschappelijk relevant is en bijdraagt aan kwaliteit, doelmatigheid en betaalbaarheid van zorg. Bij de casus praktijkvariatie in de behandeling van een lagerughernia bleek bijvoorbeeld dat alleen het in kaart brengen van de huidige situatie onvoldoende is om data te verkrijgen. De onderzoeksgroep moest ook onderbouwen welke kwaliteitsverbeteringen in gang gezet zouden worden naar aanleiding van het onderzoek en of resultaten met partijen zoals de wetenschappelijke vereniging besproken zouden worden.
De voorwaarden waaraan onderzoekers moeten voldoen zijn echter niet altijd even duidelijk, databeheerders kunnen onderzoekers ook faciliteren door concreter en transparanter te maken waarop onderzoeksvragen beoordeeld worden en zo een sneller aanvraagproces bewerkstelligen. Het Nivel en Vektis doen een stap in de goede richting door toegekende aanvragen op hun website te publiceren.
Verder moeten de onderzoekers financiële middelen verzamelen om de kosten voor de aanvraag te dekken. Bij het CBS en het Nivel zijn deze kosten relatief beperkt, maar bij andere dataleveranciers kan dat tot ver boven de 10.000 euro oplopen. De kosten zijn afhankelijk van het aantal aangevraagde data, de koppeling tussen verschillende databases, de complexiteit van de datadefinitie en de tijd die gemoeid is met het laten aggregeren van de data. De kosten zijn daarom pas bekend na de beoordeling van de aanvraag. Het is altijd veel goedkoper dan zelf data verzamelen, maar het is vooraf niet te voorspellen wat de kosten zullen zijn.
Stap 4: Werken met de data
De verschillen in structuur en toegankelijkheid van databases bepalen op welke manier onderzoekers met de data kunnen werken. De onderzoeker moet hier rekening mee houden bij de selectie van de database, het opstellen van een analyseplan en het duiden van de onderzoeksresultaten. Vanuit sommige databases, zoals openDIS, Vektis open data en de ZiNL-transparantiekalender, kunnen data direct gedownload worden. Dit zijn echter geaggregeerde data en het detailniveau ervan is beperkt. In onze onderzoeken wilden wij het liefst zelf met data op patiëntniveau werken, maar liepen wij er tegenaan dat bij bepaalde dataleveranciers alleen geaggregeerde data verkregen kunnen worden (DHD, Vektis) in verband met mogelijke herleidbaarheid tot individuele personen. Dat is begrijpelijk, maar daardoor moet de onderzoeker vooraf zelf over goede kennis beschikken om de keuzes die gemaakt worden bij het aggregeren van data te begrijpen en de effecten hiervan op de onderzoeksresultaten te kunnen duiden. Het CBS biedt onderzoekers wel de kans om met ruwe data aan de slag te gaan, waardoor de onderzoeker volledige controle heeft over de data en zelfstandig aanpassingen kan doorvoeren. Nadeel van de CBS-data is dat de onderzoeker zelf databestanden moet koppelen en dat is tijdrovend.
Zoektocht
Het gebruik van routinematig verzamelde data voor onderzoek heeft ons veel voordelen gebracht. We hebben een representatieve onderzoekspopulatie in kaart kunnen brengen, met lange follow-up en weinig patiëntuitval. Bovendien hebben we door deze data te gebruiken veel tijd en moeite kunnen besparen, die prospectieve dataverzameling had gekost.
Het was echter wel een zoektocht om in het woud van beschikbare data de juiste databron te vinden, haar ook daadwerkelijk te bemachtigen en te mogen bewerken. Eén loket voor medische data zal deze zoektocht in de toekomst hopelijk een stuk vergemakkelijken.
TABEL 2. VERSCHILLEN TUSSEN DATABEEERDERS
ONDERZOEK
Juliëtte van Munster, arts-onderzoeker afdeling Keel-, Neus-, en Oorheelkunde, LUMC, Leiden
Vera de Weerdt, arts-onderzoeker Talma Instituut, VU Amsterdam, Amsterdam UMC, locatie AMC
Geeske Hofstra, onderzoeker Talma Instituut, VU Amsterdam
Eric van der Hijden, projectleider thema gepaste zorg Talma Instituut, VU Amsterdam, Zilveren Kruis Zorgverzekeringen
Lees ook- Er zijn nog geen reacties


















